
提到敏感词过滤,经过简单思考,你没有想到Trie的话,那么你就不要思考了,这篇文章很适合你。如果你想到了,这篇文章也不失一篇很好的参考。
有经验的开发者都会说到用字典树来实现敏感词检测过滤等功能,字典树即本文所谈论的对象Trie。
他的别名除了字典树,还有很多:前缀树、单词查找树、键树。跟很多人一样,我也格外喜欢前缀树(Prefix Tree)这个昵称。
第一部分 什么是Trie,首先带你感性认识下Trie
把一个字符串拆分为一个一个字符,把每一个字符按照先后顺序,放到一颗空树的节点上,把节点和边连接起来就是整个字符串。对于多个字符串,按照单个串的处理方式,如果前缀相同就不在新增节点。这样构造起来的数据结构成为Trie。
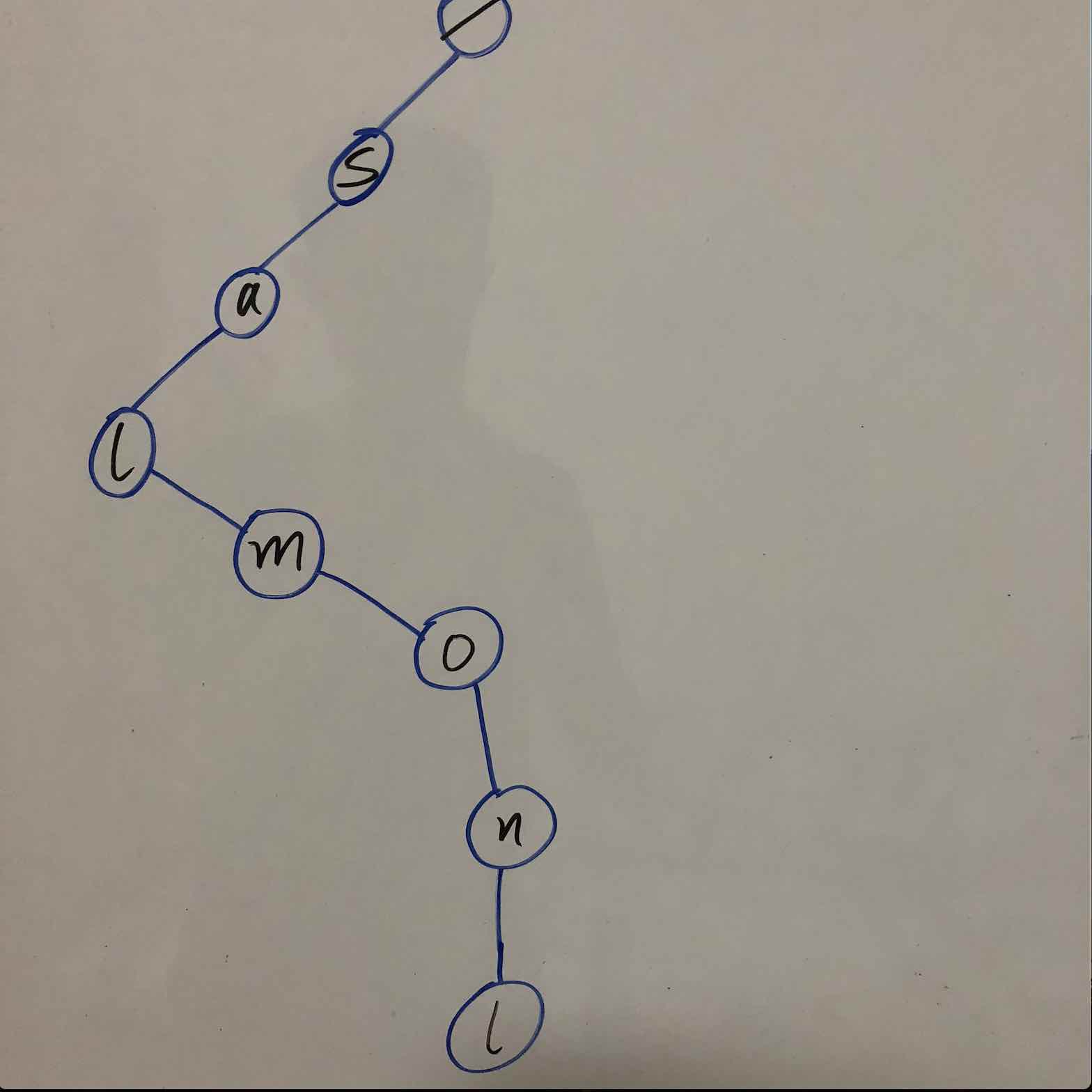
先来把一个字符串’salmonl’挂到树上, 如下图:
接下来把多个字符串挂到树上, ‘大傻叉’, ‘傻叉’, ‘逆流而上的鱼’,’逆流而上的人生’。如下图:

以上我们可以总结出Trie的特点
0、根节点不包含字符,除根节点外的节点都包含一个字符。
1、从跟节点到某一节点(是字符的终止节点),路径上经过的节点连接起来,就是该节点对于的字符串。
2、Trie是一颗多叉树。
3、具有相同前缀的字符串,共用前缀节点。比如’逆流而上的鱼’,’逆流而上的人生’两个串共用前面四个节点。注意’傻叉’不能共用’大傻叉’傻这个节点。
第二部分 那么Trie有那些应用场景呢
一、敏感词检索
算法:
0、构建Trie树
1、遍历目标字符串中的每一个字符,如果字符不存在,继续下一个。
2、如果字符存在,从该字符下一个字符开始遍历,匹配成功后直接返回匹配字符长度,然后跳过这个长度并不是+1, 算是优化了【匹配到一个词后直接返回,没有往下找最长】,否则回到第1步
3、重复1-2
具体实现参考博文: PHP基于Trie实现敏感词检索
二、敏感词过滤、替换【敏感词替换为*】
算法:
0、构建Trie树
1、遍历目标字符串中的每一个字符,如果字符不存在,继续下一个。
2、如果字符存在,从该字符下一个字符开始遍历,【这里可以记一个步长,设置跳过多少个字符】匹配成功则收集到数组中,否则回到第1步
3、重复1-2
具体实现参考博文: 《PHP基于Trie实现敏感词替换》
三、基于Trie实现AC自动机,过滤敏感词
算法:
0、构建Trie树
1、在Trie树上建失配指针,成为AC自动机
2、在AC自动机上查找字符串
AC自动机高效实现敏感词过滤: 《PHP实现AC自动机高效过滤敏感词(注:具体的实现代码涉及内容您可能没有阅读权限)
四、词频统计
算法:
0、定义包含词频计数的节点
class Node
{
// 节点字符
public $data;
// 存放子节点引用(因为有任意个子节点,所以靠数组来存储)
public $children = [];
// 是否是字符串结束字符
public $isEndingChar = false;
// 出现的次数,用于计算出现频率
public $frequecy;
}
1、遍历字符串文本,构建Trie。生成Trie的过程中,遇到相同的单词,$frequecy + 1。过程可参考《用Trie树统计词频》
2、遍历生成好的Trie(可使用深度优先搜索算法DFS, Depth-First-Search), 得到全部词出现的次数。
3、按次数排序(可通过快速排序算法)词,取出Top100。
五、前缀匹配
第三部分 算法复杂度
Trie树明显的空间换时间。
假如我们有10000个关键词k,每个关键词长度都是m, 查找字符串长度为n。
一、时间复杂度
O(n)
最坏情况,查找字符串中的每一个字符都需要遍历一次,每次遍历的时候沿着一个分支前进,忽略不记。
注:AC自动机的时间复杂度理论应该更低一些,均摊还是线性时间复杂度。
二、空间复杂度
最坏的情况,关键词中的字符都不一样,空间复杂度O(m * k)
注:如果不按字符存,存m个字符串,空间复杂度也是O(m), 存字符串的长度比存字符的长度长啊,这个怎么算?
第四部分 应用
能处理的常见相关问题, 海量数据处理问题
a、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
算法:参考这里
0、根据分治思想,拆分1G单词到小文件中,计算需要多少个n小文件。
拆分文件数计算, 如下图:

1、遍历全部单词word,通过散列函数确定放到那个小文件,hash(word) / n = 分发到小文件。
2、使用Trie来统计每个小文件的Top100。【当然hash也可以】
3、通过小顶堆来确定最终Top100。(小顶堆的原理和实现参考博文: 堆及堆排序PHP实现)
b、1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
c、 一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
d、寻找热门查询:搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录,这些查询串的重复读比较高,虽然总数是1千万,但是如果去除重复和,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就越热门。请你统计最热门的10个查询串,要求使用的内存不能超过1G。