
Excel是Microsoft电子表格软件,目前常用的是xlsx格式(Microsoft Excel 2007 及以上版本创建的电子表格文档)。Go语言操作xlsx格式excel文件,有3个常见的库:
● xlsx [github地址:https://github.com/tealeg/xlsx]
● unioffice [github地址:https://github.com/unidoc/unioffice]
● excelize [github地址: https://github.com/qax-os/excelize]
一句话总结差异:xlsx和excelize只支持xlsx文件读写,unioffice支持office三件套;xlsx比较早,目前已经不维护;excelize提供的API和文档比较易用, 流式读写处理大数据集性能较高,特别活跃;unioffice API不易用


From: 图片来源参考
注:可以重点关注Go和Java的性能和内存使用情况,区别很大,这是语言层面决定的,Jave内存管理器、GC都是优化过的,Go并发很棒,但是不是万金油,可以发现Java优势
一、excelize基础库简介
1、github地址: https://github.com/qax-os/excelize
2、作者: 续日【花名: 旭日】
3、特点
● 支持 XLSX / XLSM / XLTM / XLTX/ XLAM格式
● 高度兼容带有样式、图片(表)、透视表等
● 提供流式读写 API,用于处理包含大规模数据的工作簿
4、Go版本1.16及以上
5、钉钉交流群号:30047129
二、关于写
1、写单元格
根据给定的工作表名和单元格坐标,设置单元格的值。【此功能是并发安全的】
func (f *File) SetCellValue(sheet, cell string, value interface{}) error
例
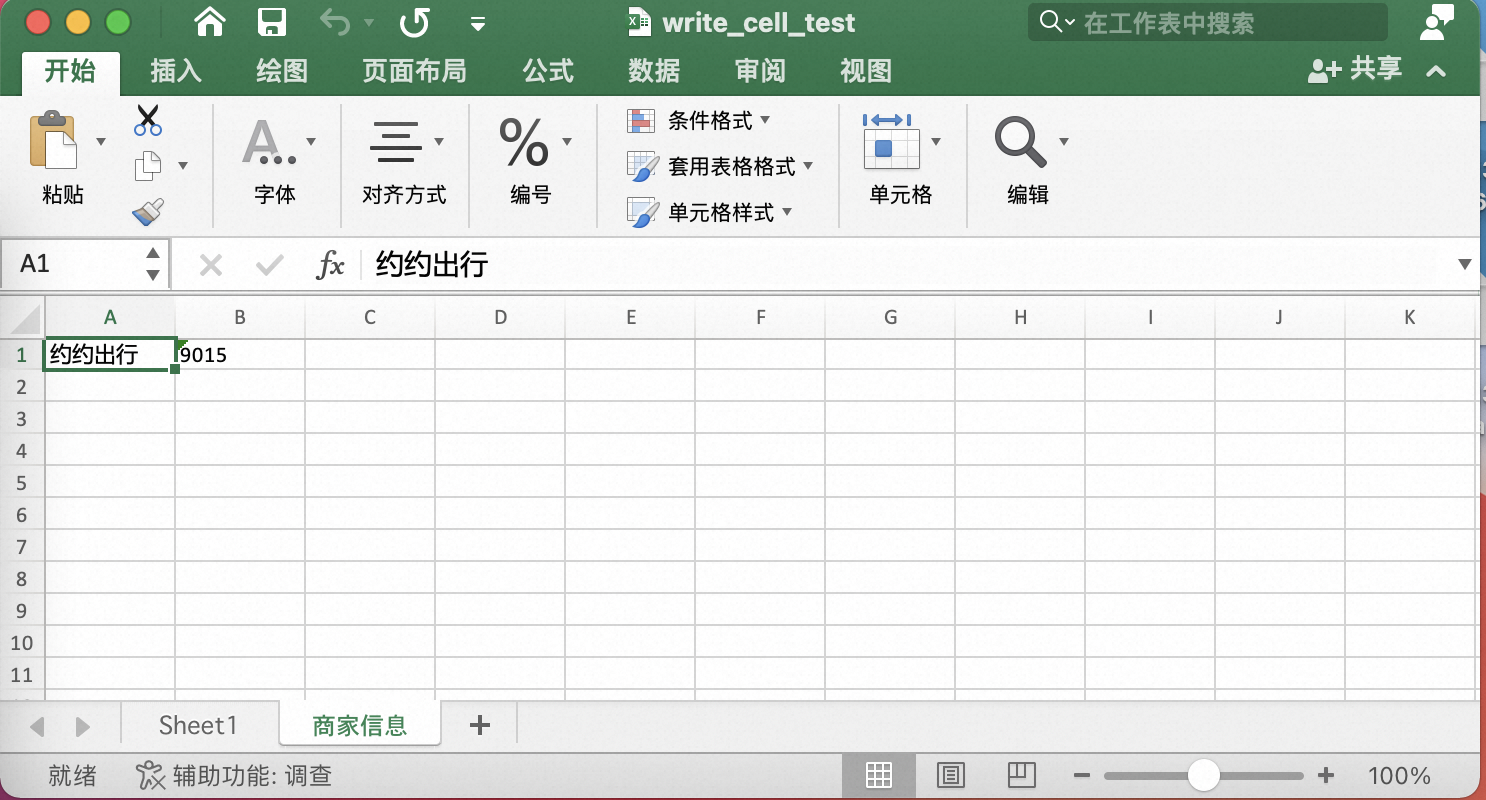
excel.SetCellValue(sheetDefault, "A1", "约约出行")
具体案例
import (
"fmt"
"os/user"
"testing"
"github.com/xuri/excelize/v2"
)
func TestWriteCell(t *testing.T) {
var sheetDefault = "Sheet1"
var sheetSpinfo = "商家信息"
excel := excelize.NewFile()
defer func() {
if err := excel.Close(); err != nil {
fmt.Println(err)
}
}()
excel.NewSheet(sheetDefault)
_ = excel.SetCellValue(sheetDefault, "A1", "约约出行")
_ = excel.SetCellValue(sheetDefault, "A2", "曹操出行")
index, _ := excel.NewSheet(sheetSpinfo)
_ = excel.SetCellValue(sheetSpinfo, "A1", "约约出行")
_ = excel.SetCellValue(sheetSpinfo, "B1", "9015")
excel.SetActiveSheet(index)
u, err := user.Current()
if err != nil {
t.Fatal(err)
}
fileName := u.HomeDir + "/Desktop/write_cell_test.xlsx"
if err := excel.SaveAs(fileName); err != nil {
fmt.Println(err)
}
fmt.Println("done")
}
效果
2、按行写
根据给定的工作表名称、起始坐标和 slice 类型引用按行赋值。【此功能是并发安全的】
func (f *File) SetSheetRow(sheet, cell string, slice interface{}) error
例
titleSlice := []interface{}{}
excel.SetSheetRow(sheetName, "A1", &titleSlice)
具体案例
import (
"fmt"
"os/user"
"testing"
"github.com/xuri/excelize/v2"
)
type DayData struct {
Spcode string
Spname string
CityName string
Date string
WrkDriverCnt int64
EOrderCnt int64
}
func TestWriteLine(t *testing.T) {
var sheetName = "Sheet1"
excel := excelize.NewFile()
defer func() {
if err := excel.Close(); err != nil {
fmt.Println(err)
}
}()
index, err := excel.NewSheet(sheetName)
if err != nil {
fmt.Println(err)
return
}
titleSlice := []interface{}{"商家编码", "商家名称", "日期", "有效出车数", "完单司机量"}
_ = excel.SetSheetRow(sheetName, "A1", &titleSlice)
datas := getMockData()
for idx, data := range datas {
axis := fmt.Sprintf("A%d", idx+2)
tmpData := []interface{}{data.Spcode, data.Spname, data.Date, data.WrkDriverCnt, data.EOrderCnt}
_ = excel.SetSheetRow(sheetName, axis, &tmpData)
}
excel.SetActiveSheet(index)
u, err := user.Current()
if err != nil {
t.Fatal(err)
}
fileName := u.HomeDir + "/Desktop/day_detail.xlsx"
if err := excel.SaveAs(fileName); err != nil {
fmt.Println(err)
}
fmt.Println("done")
}
func getMockData() []DayData {
return []DayData{
{
Spcode: "9389",
Spname: "鞍马出行",
CityName: "广州市",
Date: "20230301",
WrkDriverCnt: 100,
EOrderCnt: 200,
},
{
Spcode: "9389",
Spname: "鞍马出行",
CityName: "广州市",
Date: "20230302",
WrkDriverCnt: 300,
EOrderCnt: 400,
},
{
Spcode: "9389",
Spname: "鞍马出行",
CityName: "广州市",
Date: "20230303",
WrkDriverCnt: 500,
EOrderCnt: 600,
},
}
}
注意事项
● slice需要传入地址
如果不涉及到单元格合并,那么直接拼逗号分隔的字符串,保存为csv文件,是最简单的
3、合并单元格
根据给定的工作表名和单元格坐标区域合并单元格
func (f *File) MergeCell(sheet, hCell, vCell string) error
● 合并区域内仅保留左上角单元格的值,其他单元格的值将被忽略
● 如果给定的单元格坐标区域与已有的其他合并单元格相重叠,已有的合并单元格将会被删除
例
f.MergeCell("Sheet1", "A1", "A2")
具体案例

合并行
// ...
for i, title := range titles {
excelCol := numToExcelColName(i + 1)
bCel := fmt.Sprintf("%s%d", excelCol, 1)
f.SetCellValue("Sheet1", bCel, title)
// ...
eCel := fmt.Sprintf("%s%d", excelCol, 2)
f.MergeCell("Sheet1", bCel, eCel)
}
// ...
数字转换Excel列方法
// numToExcelColName 将数字转换为 Excel 列名,例如 1 转换为 A,27 转换为 AA
func numToExcelColName(num int) string {
var colName string
for num > 0 {
mod := (num - 1) % 26
colName = string(rune('A'+mod)) + colName
num = (num - mod) / 26
}
return colName
}
// 自带方法 excelize.ColumnNumberToName()
合并列
// 定义指向指标和等级的指针
var iIndex, gIndex int64
// ...
for _, tplIndicator := range tplIndicators {
// 写指标
ibCel := fmt.Sprintf("%s%d", numToExcelColName(iIndex), 1)
f.SetCellValue("Sheet1", ibCel, tplIndicator.Name)
// ...
// 写等级
for _, tplGrade := range tplGrades {
for _, gitem := range gradeItems {
gCel := fmt.Sprintf("%s%d", numToExcelColName(gIndex), 2)
f.SetCellValue("Sheet1", gCel, tplGrade.Name+gitem)
gIndex++
}
}
// 合并指标单元格
ieIndex := gIndex - 1
ieCel := fmt.Sprintf("%s%d", numToExcelColName(ieIndex), 1)
f.MergeCell("Sheet1", ibCel, ieCel)
iIndex = gIndex
}
4、流式写入
流式写入是一种将数据流式地写入磁盘或其他媒介的方法。它的原理是将大数据分成较小的块,逐一写入磁盘或缓存中,而不是一次性将所有数据写入
func (f *File) NewStreamWriter(sheet string) (*StreamWriter, error)
func (sw *StreamWriter) SetRow(cell string, values []interface{}, opts ...RowOpts) error
具体案例
func TestStreamWrite(t *testing.T) {
excel := excelize.NewFile()
// 获取流式写入器
sw, err := excel.NewStreamWriter("Sheet1")
if err != nil {
t.Error("获取流式写入器失败: " + err.Error())
return
}
// 按行写入
if err := sw.SetRow("A1", []interface{}{"商家编码", "商家名称", "日期", "有效出车数", "完单司机量"}); err != nil {
t.Error("获取流式写入器失败: " + err.Error())
return
}
rand.Seed(time.Now().Unix())
for i := 2; i < 10000; i++ {
tmp := []interface{}{
fmt.Sprintf("%d", rand.Intn(1000)),
"约约出行",
"20230518",
fmt.Sprintf("%d", rand.Intn(1000)),
fmt.Sprintf("%d", rand.Intn(1000)),
}
_ = sw.SetRow("A"+strconv.Itoa(i), tmp)
}
// 调用 Flush 函数来结束流式写入过程
if err = sw.Flush(); err != nil {
t.Error("结束流式写入失败: " + err.Error())
return
}
// 保存表格
u, err := user.Current()
if err != nil {
t.Fatal(err)
}
fileName := u.HomeDir + "/Desktop/stream_write_detail.xlsx"
if err := excel.SaveAs(fileName); err != nil {
t.Error(err)
return
}
fmt.Println("done")
}
注意事项
● 流失写入必须调用 Flush 函数来结束流式写入过程【如果忘了调用,excel有内容,但是打开提示文件异常】
● 普通函数不能与流式函数混合使用在工作表中写入数据【普通的函数不会报错,但是不生效】
5、性能:普通VS流式
在本地跑了下两者写入的性能对比,指定行,固定5列,可以看到1000行以内性能和内存使用差异不大,实际工作中如果低于1000行,可以不用考虑流式写入
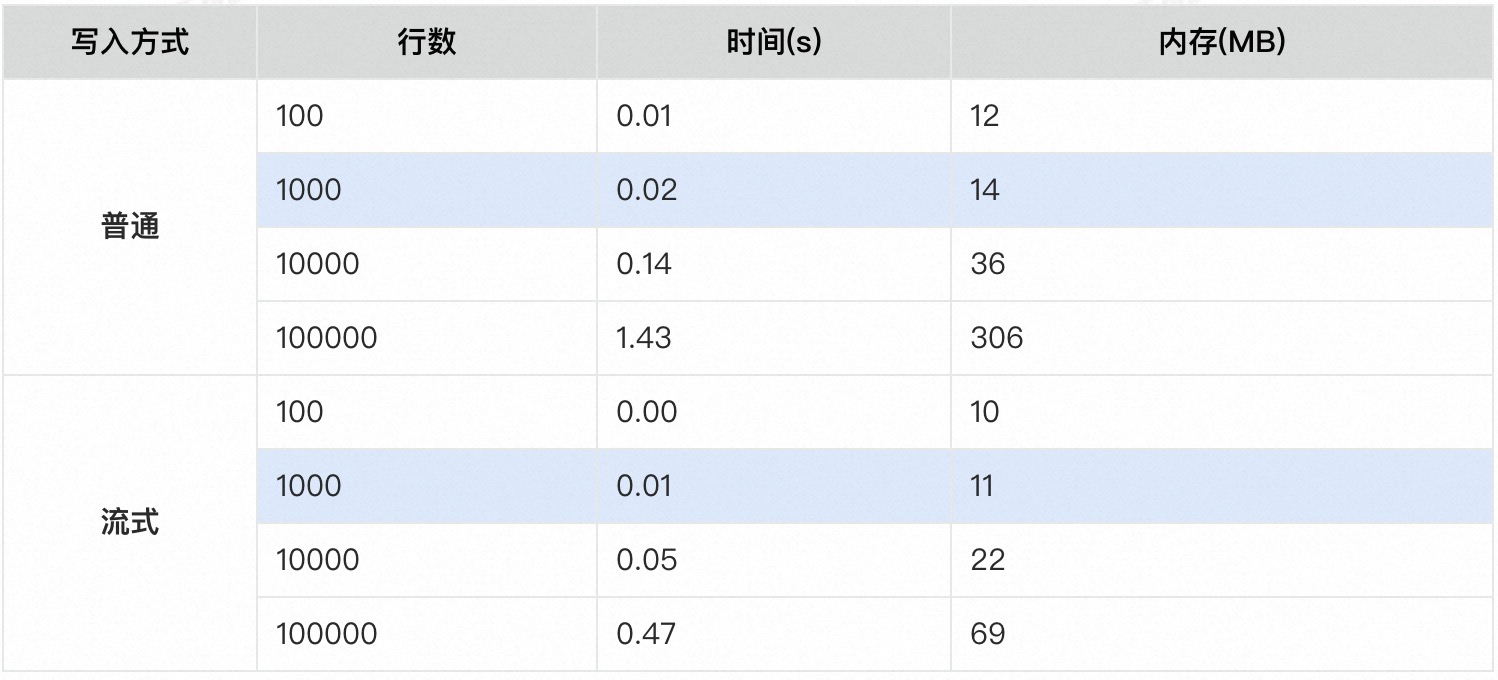
以上结果在本地机器执行(机器参数:MacBook Pro (13-inch, M1, 2020); 芯片: M1; 内存:16G)
三、关于读
1、本地读
func OpenFile(filename string, opts ...Options) (*File, error)
具体案例
func TestReadLocal(t *testing.T) {
u, err := user.Current()
if err != nil {
t.Fatal(err)
}
fileName := u.HomeDir + "/Desktop/day_detail.xlsx"
f, err := excelize.OpenFile(fileName)
if err != nil {
fmt.Println(err)
}
defer func() {
if err := f.Close(); err != nil {
fmt.Println(err)
}
}()
rows, err := f.GetRows("Sheet1")
if err != nil {
fmt.Println(err)
return
}
for _, row := range rows {
fmt.Printf("%+v\n",row)
}
fmt.Println("done")
}
执行结果
=== RUN TestReadLocal [商家编码 商家名称 日期 有效出车数 完单司机量] [9389 鞍马出行 20230301 100 200] [9389 鞍马出行 20230302 300 400] [9389 鞍马出行 20230303 500 600] done --- PASS: TestReadLocal (0.00s) PASS
2、io.Reader读
func OpenReader(r io.Reader, opts ...Options) (*File, error)
简单读并处理
func Import(ctx context.Context, gCtx *gin.Context, req *params) error {
mfile, fheader, err := gCtx.Request.FormFile("file")
if err != nil {
return err
}
f, err := excelize.OpenReader(mfile)
defer func() {
if err := f.Close(); err != nil {
return err
}
}()
rows, err = f.GetRows("Sheet1")
// ... do something
// err = bucket.PutObject(objectKey, mfile)
return nil
}
读的具体方法
// OpenReader read data stream from io.Reader and return a populated
// spreadsheet file.
func OpenReader(r io.Reader, opt ...Options) (*File, error) {
b, err := ioutil.ReadAll(r)
if err != nil {
return nil, err
}
// ...
}
// io package
func ReadAll(r Reader) ([]byte, error) {
b := make([]byte, 0, 512)
for {
if len(b) == cap(b) {
// Add more capacity (let append pick how much).
b = append(b, 0)[:len(b)]
}
n, err := r.Read(b[len(b):cap(b)])
b = b[:len(b)+n]
if err != nil {
if err == EOF {
err = nil
}
return b, err
}
}
}
具体read方法【multipart下的file结构体,没有看到具体read实现,暂时用bytes包来说明】
// bytes package
type Reader struct {
s []byte
i int64 // current reading index
prevRune int // index of previous rune; or < 0
}
// Read implements the io.Reader interface.
func (r *Reader) Read(b []byte) (n int, err error) {
if r.i >= int64(len(r.s)) {
return 0, io.EOF
}
r.prevRune = -1
n = copy(b, r.s[r.i:])
r.i += int64(n)
return
}
处理内容并上传OSS
一个文件打开读取后,在直接上传,上传的文件内容为空,解决的两个思路
思路一: 重建reader
// 思路一 重建reader
func Import(ctx context.Context, gCtx *gin.Context, req *params) error {
mfile, fheader, err := gCtx.Request.FormFile("file")
contents, err := ioutil.ReadAll(mfile)
// 内容处理并落库
f, err := excelize.OpenReader(bytes.NewReader(contents))
defer func() {
if err := f.Close(); err != nil {
return err
}
}()
rows, err = f.GetRows("Sheet1")
// 上传OSS
err = bucket.PutObject(objectKey, bytes.NewReader(contents))
return nil
}
思路二 seek
// 思路二 seek
func Import(ctx context.Context, gCtx *gin.Context, req *params) error {
mfile, fheader, err := gCtx.Request.FormFile("file")
// 内容处理并落库
f, err := excelize.OpenReader(mfile)
defer func() {
if err := f.Close(); err != nil {
return err
}
}()
rows, err = f.GetRows("Sheet1")
// seek
mfile.Seek(0, io.SeekStart)
// 上传OSS
err = bucket.PutObject(objectKey, mfile)
return nil
}
3、流式读
func (f *File) Rows(sheet string) (*Rows, error)
具体案例
rows, err := f.Rows("Sheet1")
if err != nil {
fmt.Println(err)
return
}
for rows.Next() {
row, err := rows.Columns()
if err != nil {
fmt.Println(err)
}
for _, colCell := range row {
fmt.Print(colCell, "\t")
}
fmt.Println()
}
if err = rows.Close(); err != nil {
fmt.Println(err)
}
四、常见问题
1、时间格式
创建excel 默认为 time.Time 类型的单元格的值设置 m/d/yy h:mm 数字格式
const FormatToDayStr = "1/2/06 15:04"
func date2Time(date string) (time.Time, error) {
return time.ParseInLocation(FormatToDayStr, date, time.Local)
}
解法一:设置时间格式
解法二:设置文本样式
f := excelize.NewFile()
const TextFmt = 49
// 时间列设置为文本格式
dateStyle, err := f.NewStyle(&excelize.Style{
NumFmt: TextFmt,
})
f.SetColStyle("Sheet1", excelCol, dateStyle)
解法三:自定义格式
exp := "yyyy-m-d h:mm:ss"
style, err := f.NewStyle(&excelize.Style{CustomNumFmt: &exp})
2、浮点数
excel输入带百分号的小数,默认保留2位小数。超过的会丢掉
解法:列格式设置为文本或自定义格式
exp := "0.0000%"
style, err := f.NewStyle(&excelize.Style{CustomNumFmt: &exp})
3、数据校验
● 校验单元格值必须大于指定值
● 校验单元格值属于某个范围
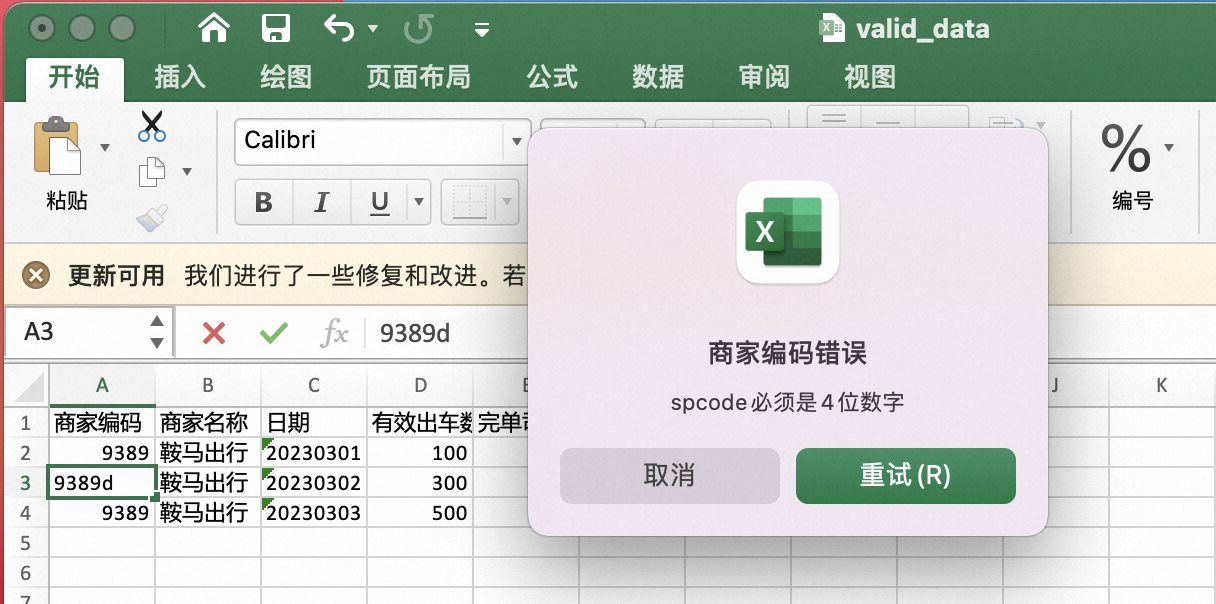
dv := excelize.NewDataValidation(true)
dv.SetSqref("A2:A10")
dv.SetRange(1000, 9999, excelize.DataValidationTypeWhole, excelize.DataValidationOperatorBetween)
dv.SetError(excelize.DataValidationErrorStyleStop, "商家编码错误", "spcode必须是4位数字")
excel.AddDataValidation("Sheet1", dv)
效果
五、感受
1、操作excel本身会比较重,但是用excelize库,你会觉得很轻
2、excelize目前主要靠作者一个人维护,很赞
3、execlize 写入大量数据 占用内存比Java 高很多,为什么
这可能与Golang和Java的内存管理机制有关。Golang虽然是一种高效的编程语言,但在内存管理方面相对更加简单,它使用了垃圾回收机制来自动释放不再使用的内存。垃圾回收由Go运行时系统自动管理,这样程序员就可以专注于编写代码,而不必担心内存管理问题。
然而,这种自动化的内存管理机制可能会导致一些额外的内存开销,因为它需要一些额外的内存来维护垃圾回收器的数据结构。另外,Golang的内存分配器可能会分配额外的内存块来避免内存碎片。
相比之下,Java的内存管理机制相对更加复杂,使用了一种称为“垃圾回收器”的机制来释放不再使用的内存。Java的内存管理器比Golang更加智能,因为它可以自动识别程序中的内存泄漏问题,并尝试解决这些问题。同时,Java的内存管理器也会在必要时进行内存压缩和碎片整理,以最大限度地利用可用内存。
因此,尽管Golang是一种快速、高效的编程语言,但由于其内存管理机制的不同,它可能需要更多的额外内存来处理大量数据【From ChatGPT3.5】
4、TODO
六、参考
1、excelize手册【官方中文手册】
2、第 139 期 2022-11-03 Go 语言 Excelize 开源基础库介绍【Go夜读原作者分析,go xml包如何处理xml文件,侧重原理】
3、Go常用包(二十一):360开源高性能excel库(Excelize)
4、Excelize荣获2022中国开源创新大赛一等奖
5、Golang 第三方库xlsx学习【简书,xlsx基础库读写excel用法】