
上篇文章《用户互动数据排序中数据归一化的必要性探讨》的结尾提到归一化后的数据存储到Redis sorted sets中是否对数据读写有影响,查了相关资料,推导的结论是没有影响。
这里简化描述问题,用Redis实现投票排行榜TOP3,Option1票数100,Option2票数100000,Option3票数10000000
zadd vote_rank 100 'Option1' 100000 'Option2' 10000000 'Option3'
对数据min-max归一化处理后得到数据分别是0, 0.0099901, 1
zadd vote_rank 0 'Option1' 0.0099901 'Option2' 1 'Option3'
问题:以上两种数据(对其中一种做了缩放平移的变换),redis在插入、查找、删除等操作中是否有性能上的不同?
结论:没有影响。
Redis sorted sets是通过skip list(跳跃表)和 hash table(哈希表)这两种数据结构来实现的。而跳跃表主要用来实现score排序的。
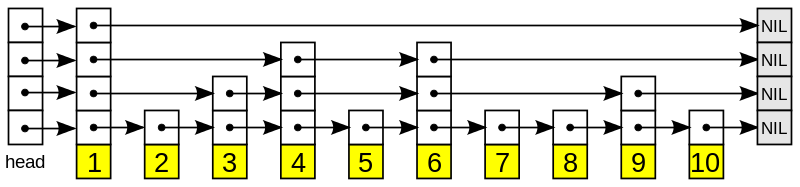
首先看一下跳跃表的一个例子(图片来之维基百科):
{kind=link}
跳跃表是一种多层次链表的数据结构,第一层是一个有序的链表,下层的元素按固定概率p(Sorted sets 中 p = 0.25)出现在上一层,所以每一层链表中的元素是前一层链表元素的子集。查找特定值从顶层头元素开始,沿着每个链表搜索,直到找到小于等于目标的最后一个元素,可以快速跳过部分列表,大大减少了比较次数(很好的解决了有序链表查找特定值的困难)
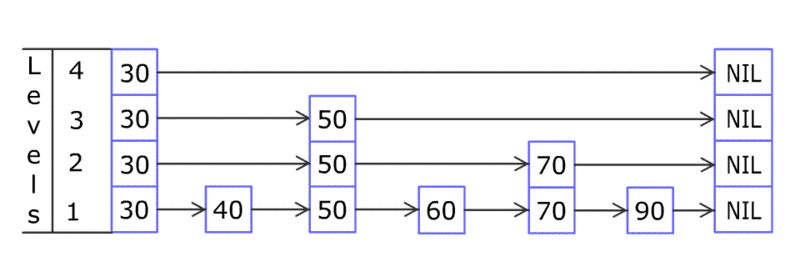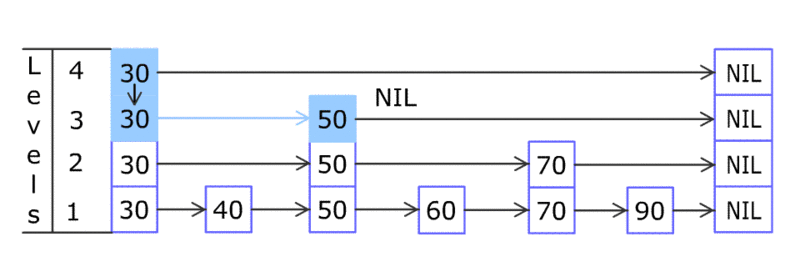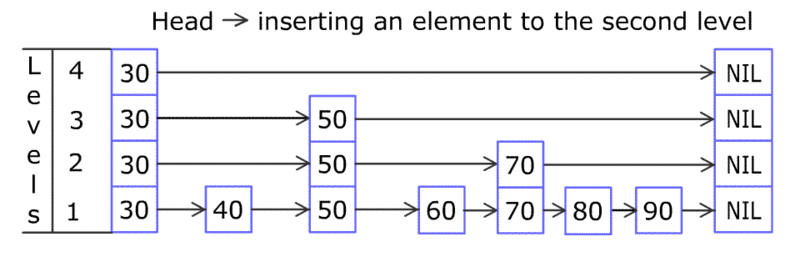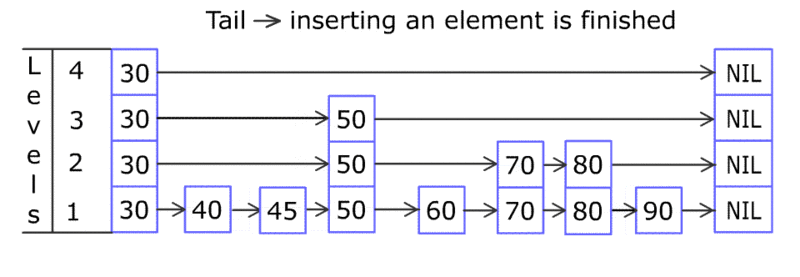
通过下图直观感受一下跳跃表的数据插入过程(图片来之维基百科)。
{kind=link}
跳跃表每次插入元素的复杂度都是O(log n), 所以性能跟数值的跨度没有关系。
(全文完)
参考:
https://zh.wikipedia.org/wiki/跳跃列表
http://dsqiu.iteye.com/blog/1705530
https://redisbook.readthedocs.io/en/latest/internal-datastruct/skiplist.html
http://czrzchao.com/redisSourceSkiplist