
最近在工作中看到了基于用户互动数据排序的两种实现思路,一种是“分权加和”,直接根据权重来计算数值,另一种在第一种的基础上对数据做了归一化处理。当然两种方式都是没问题的,毕竟都经过线上的验证。
做了归一化处理,看似更科学、更严谨,既然不做也可以,那么归一化处理到底有没有好处,是不是有必要呢?
下面首先具体展开描述下两种方式,给有需要的读者一个参考。
分权加和
第一种是常规方式,这里简称“分权加和”,具体来说就是,不同维度根据具体业务情况事先约定好权重系数,把各个维度的数据乘以对应的权重系数加和,得到一个数值,用来排序。
例如某业务有两个维度x, y,两个维度的数据分别是x_count, y_count, 根据市场调研或者产品策略约定x维度权重系数为x_weight,y维度权重系数为y_weight, 那么,可以很容易得到一个排序分值score = x_count * x_weight + y_count * y_weight。具体业务场景,比如博客、微博的博文排序。
算法和伪码实现:
0、格式化数据。把数据格式化到固定的维度。(为了方便说清楚,模拟了一组简化的数据场景,根据阅读数read_count, 评论数comment_count对id进行排序。实际情况可能要复杂一些,比如comment_count是互动数,包括博文的转发数,评论数,点赞数,需要有一个计算过程)
$datas = array(
array(
'id' => 10001,
'read_count' => 10,
'comment_count' => 3,
),
array(
'id' => 10002,
'read_count' => 20,
'comment_count' => 1,
),
array(
'id' => 10003,
'read_count' => 20,
'comment_count' => 3,
),
);
1、约定好各个维度的权重,采用“分权加和”得到分值
$read_weight = 0.7;
$comment_weight = 0.3;
foreach ($datas as => $data) {
$data['score'] = $data['read_count'] * $read_weight + $data['comment_count'] * $comment_weight;
}
2、存储排序项ID和分值【常用Redis的zSet】
$redis->zAdd($key, $score, $id);
数据归一化
如果读者对数据归一化不太熟悉,可以首先阅读下知乎上这个问题:特征工程中的「归一化」有什么作用?下@微调的回答。这个回答对归一化解释的比较清楚,也论证了归一化本质是一种线型变换,而线型变换不会改变原有数据的排序,所以归一化的引入对排序结果没有影响。
第二种在“分权加和”的基础上引入了数据归一化,具体来说就是对各维度的数据进行归一化处理后,再乘以权重系数,加和获取分值。
还是以上面业务的两个维度x, y为例,各维度数据还是x_count, y_count, 对应的权重系数x_weight, y_weight, 首先对各维度数据进行归一化处理(比如用min-max归一化),很容易获取到各维度的最大最小值min_x_count, max_x_count, min_y_count, max_y_count。
归一化后x_count对应的值x_count_new = (x_count – min_x_count) / (max_x_count – min_x_count), 同理y_count_new = (y_count – min_y_count) / (max_y_count – min_y_count), 在进行分权加和, 得到score = x_count_new * x_weight + y_count_new * y_weight。
算法和伪码实现:
0、格式化数据。把数据格式化到固定的维度
1、计算各个维度最大值max, 最小值min
$max_read_count = 20; $min_read_count = 10; $max_comment_count = 3; $min_comment_count = 1;
2、对各个维度数据进行min-max归一化
// 正常的使用归一化 $read_score = ($data['read_count'] - $min_read_count) / ($max_read_count - $min_read_count); $comment_score = ($data['comment_count'] - $min_comment_count) / ($max_comment_count - $min_comment_count); // 如果max 和 min 之间相差太多(例:max = 100000000, min = 1),可以取对数后,再处理 $read_score = (log(1 + $data['read_count']) - log(1 + $min_read_count)) / (log(1 + $max_read_count) - log(1 + $min_read_count)); $comment_score = (log(1 + $data['comment_count']) - log(1 + $min_comment_count)) / (log(1 + $max_comment_count) - log(1 + $min_comment_count));
3、对归一化后的数据进行“分权加和”
$data['score'] = $read_score * 0.7 + $comment_score * 0.3;
4、存储排序项ID和分值【常用Redis的zSet】
$score = $redis->zAdd($key, $score, $id);
两种方式结果比较
实际场景下两种方式计算的分值,示例如下图【右边是经过归一化处理的】:
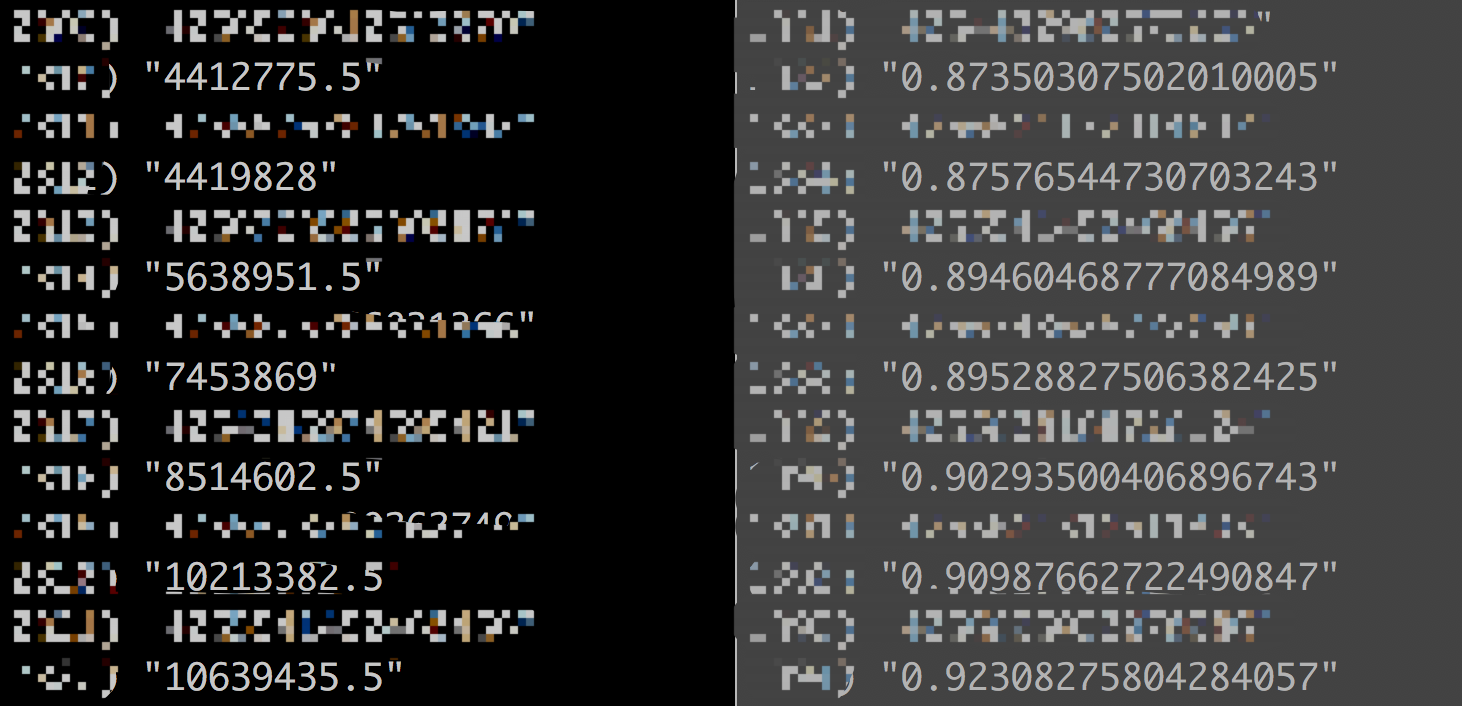
一开始还在思考,不归一化后数据太大,会不会对存储有影响,后来看到《Redis设计与实现》上提到zset value是double类型的,所以不存在这个问题
总结:
0、一般情况下(value不是极大),可以不用对数据归一化处理。归一化处理增加了一些复杂性,同时需要一定的计算时间,虽然是异步排序,但是实时性上有影响。
1、value的值,是存归一化后[0,1]直接的数,还是存一个很大的数,存储上没有影响,是double类型。
2、至于存储归一化后[0,1]直接的数,有没有读和写方面的优势,还待验证。
3、以上只是个人的一些推论,如果有好的建议,欢迎留言,交流。
(全文完)
参考:
《Redis设计与实现》