
对投票数据统计的时候发现了Redis Hash类型的一个大坑,单个key中field过多,导致取不出来。特记录下尝试解决和探索的过程。
第一阶段:问题描述
一个投票类的产品,对单个选项mid投票成功后,记录了总票数,还记录了用户投票日志(可以理解成投票明细),用的都是Redis Hash类型来存储。投票日志的存储格式如下:
$redis->hset('vote_log', 'uid|mid|timestamp', 1);
最近,运营需要统计固定时间段每个选项投票的用户数,要的比较急,就很快写了一个脚本
算法:
0、全部取不来
1、第一次遍历,筛选出mid
2、第二次遍历,筛选出每个mid对应的uid
3、去重
4、统计数量
运行就报错:

脚本的使用内存已经设定为1024M了,查看Redis.php中163行使用的是hGetAll获取全量数据,估计是数据太大,登陆上Redis 使用hlens显示2700W,确实太大了,改为hKeys获取还是一样报错。Goolge搜索了一番,发现唯一的解决方案就是使用hscan, 测试发现线上redis server版本2.4不支持hscan(hscan命令版本要求>=2.8), 顿时都绝望了,跟运营反馈数据存储集中,并且数量比较大,传统的方案统计不出来,需要时间用其他方式来处理。好在,运营了解情况后,表示可以不用统计用户数。
第二阶段:探索解决方案
但是技术上这个问题并没有解决,如何解决这个问题呢
目前分析思考结果如下:
0、使用内存足够的机器跑脚本
1、使用hscan[自己的阿里云上redis server version 3.2.11测试了hscan确实可以分页取数据]
第一种:升级redis server version到2.8以上
第二种:导出redis key,导入高版本redis server中
具体实施的解决方案,还在探索中…(redis hash key导出在尝试中,如果大家有好的建议,欢迎留言)
针对hscan这里有一个地方需要格外注意(scan不存在这个问题)
观察下面几条命令,我们看到vote_info中现在有4个键值对,但是我们设置hscan的count为2,还是返回了全部内容,并不是预期的2条
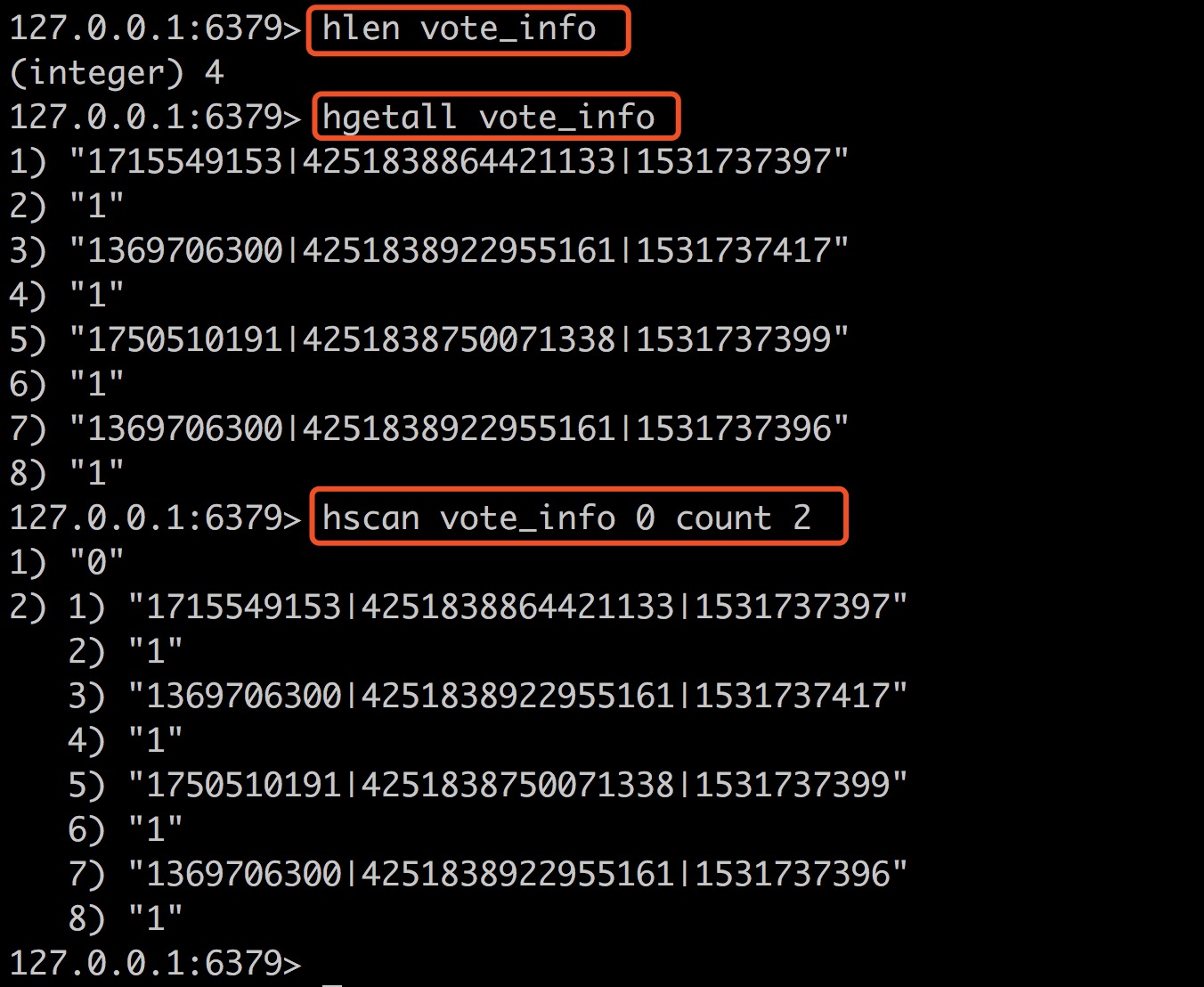
我们知道Redis Hashes是由ziplist(压缩列表)和字典(Dict)两种编码方式实现,当我们创建一个空的Hashes的时候使用的ziplist编码, 当某个键或某个值的长度大于hash_max_ziplist_value设定的值,会切换的Dict编码,还有一种情况也会切换就是ziplist的entries(节点数)大于hash_max_ziplist_entries。hash_max_ziplist_value和 hash_max_ziplist_entries在redis.conf中设置,默认值分别是512和64。
hash-max-zipmap-entries 512 (hash-max-ziplist-entries for Redis >= 2.6)
hash-max-zipmap-value 64 (hash-max-ziplist-value for Redis >= 2.6)查看redis scan 文档,Hashes使用ziplist编码的时候,通常忽略count参数,直接返回全部元素。
打开redis.conf, 把hash_max_ziplist_entries修改为10,hset多个元素,直到hlen为11的时候,count才生效,观察下面一组命令
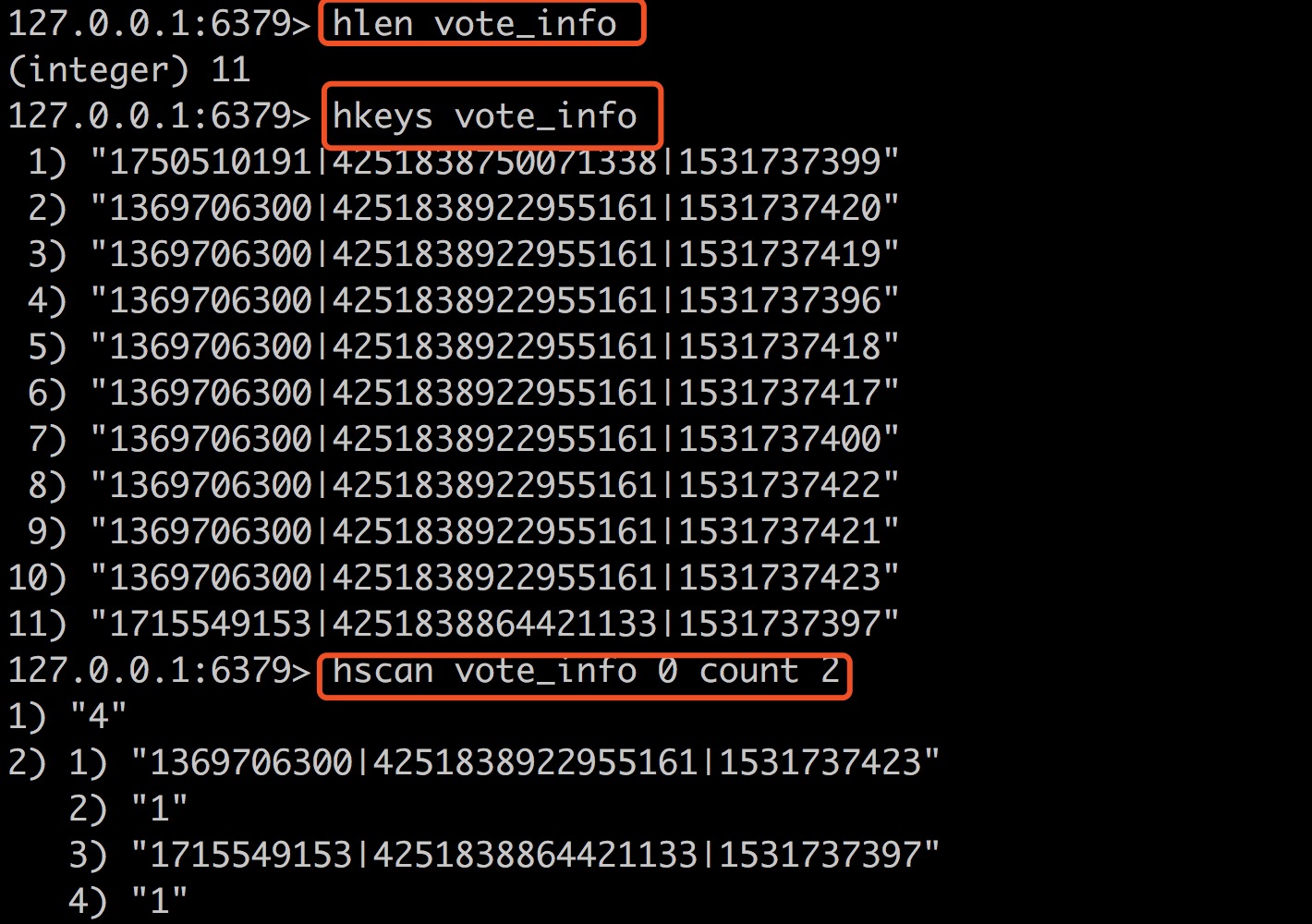
按照上面的实验,ziplist中一对key-value算一个entries,没有找到理论说明, 参考《Redis设计与实现第一版》中的结构
一个ziplist的分布结构:

key-value一同压入ziplist后的结构:

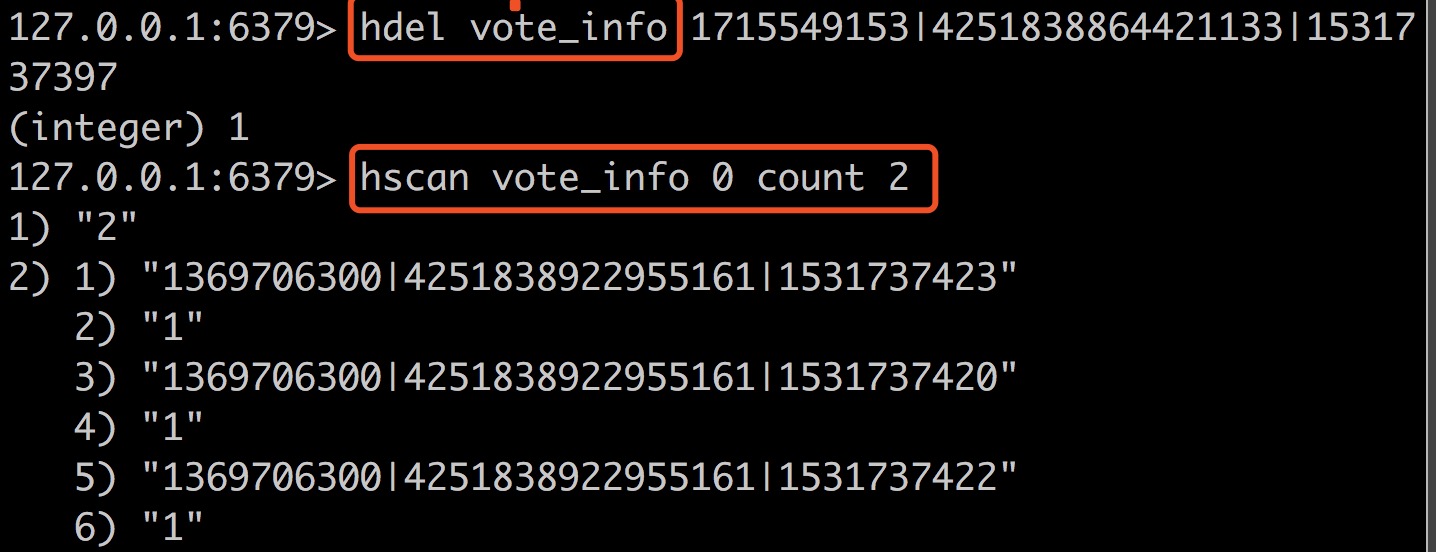
测试遗留问题:当hdel一条记录后,hscan的count选项还是生效,返回的数量也有异常,暂未找到原因
第三阶段:优化存储结构,避免问题
去年PHP开发者大会上,记得鸟哥说,避免问题也是一种解决问题的好办法。
如何存储来避免这种问题呢
方案一:存储key的优化, 按照mid来拆分key
$redis->hset('vote_log_mid', 'uid|timestamp', 1);
方案二:存储key的优化,按天来存
// 需要区分投票选项
$redis->hIncrBy('vote_log_mid_20180718', 'uid', 1);
// 不需要区分投票选项
$redis->hIncrBy('vote_log_20180718', 'uid', 1);
方案三:redis2mysql, 直接存到mysql中
–表结构
CREATE TABLE `vote_log` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增ID', `aid` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '活动ID', `feed_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'feed id', `mid` bigint(11) unsigned NOT NULL DEFAULT '0' COMMENT 'mid', `uid` bigint(11) unsigned NOT NULL DEFAULT '0' COMMENT 'uid', `create_time` bigint(11) unsigned NOT NULL DEFAULT '0' COMMENT '投票时间', `ext` varchar(64) NOT NULL DEFAULT '' COMMENT '扩展字段', PRIMARY KEY (`id`), KEY `key_a_f_c` (`aid`,`feed_id`,`create_time`), KEY `key_a_f_m` (`aid`,`feed_id`,`mid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='投票日志';
结合实际情况,虽然方案一和方案二改造起来很方便,这个日志数据并不需要实时读取,放在Redis中有对Redis误用乱用的嫌疑,也并不方便运营未知的统计需求。存到mysql中开始考虑到按照日期或者活动id来分表,查看发现不是每个月都有这样的投票活动,也不是每个活动都有投票,完全可以存一张表,等到时候数据太大了,可以写脚本清历史数据,或者手动清。
以上,选中了方案三。
其他已知的方案:
拆分key, 参考《Redis单key值过大,优化方式》
单独存一份field,参考《Redis Hash结构遍历某一个key下所有field value的方法》
第四阶段:思考总结
在解决问题的过程中,发现很多朋友遇到了类似的问题,确实值得我们深思,在当初设计存储的时候,必须要考虑到这种情况,最好的解决办法还是设计阶段提前预判和规避,就像昨天法国🇫🇷VS克罗地亚🇭🇷的世界杯决赛上解说说的,追不上姆巴佩,提前预判他的路线,打断他的进攻,不给发挥速度的机会,这也是架构设计的意义吧。
最后补充一个有趣的发现,删除hash总最后一个field后,hash key也会被删除
redis 10.235.25.242:6379> hmset salmonl_20190514 id 100 type 1 OK redis 10.235.25.242:6379> hdel salmonl_20190514 id (integer) 1 redis 10.235.25.242:6379> exists salmonl_20190514 (integer) 1 redis 10.235.25.242:6379> hdel salmonl_20190514 type (integer) 1 redis 10.235.25.242:6379> exists salmonl_20190514 (integer) 0
(全文完)
参考资料:
https://redis.io/topics/memory-optimization
https://redis.io/commands/scan#the-count-option
http://origin.redisbook.com/compress-datastruct/ziplist.html#id2
https://stackoverflow.com/questions/34503876/redis-hscan-command-cannot-limit-the-counts